Curso Python desde Cero e Introducción a Data Science y Machine Learning
Clases Live Streaming

Forecasting y Machine Learning
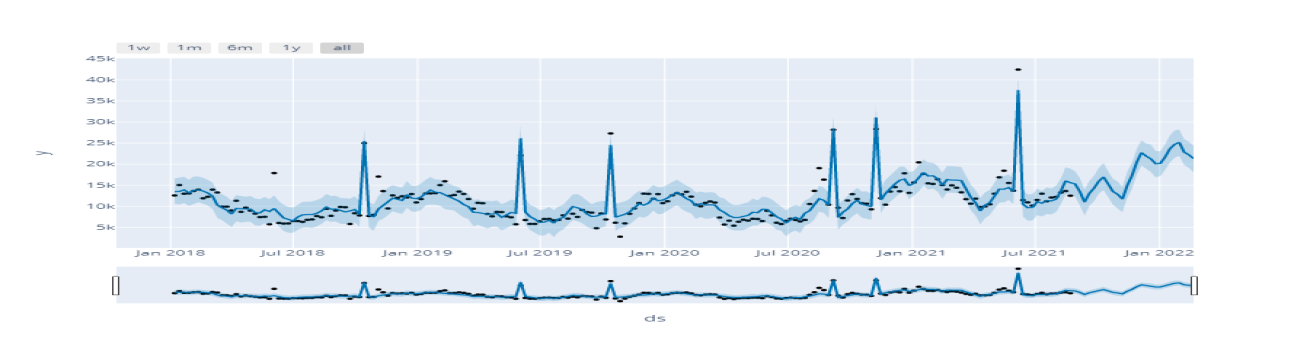

Este modelo tiene por objetivo hacer Forecast del precio de acciones de Apple, Microsoft, Google, considerando diferentes horizontes de tiempo que van desde 1 hasta 4 años.
Esta App permite predecir el sueldo de Software Developers en función de sus estudios, experiencia y país. Utiliza el modelo Random Forest para la predicción y acompaña una breve revisión de la data.
Podrás ver otras aplicaciones de Python para Machine Learning y Ciencia de Datos. Además encontrarás App creadas con el framework Django que junto a Python permiten su implementación.
Podemos aplicar Python a diversos temas laborales, entre estos encontramos las potentes herramientas para la construcción de modelos predictivos aplicados a los procesos de Forecast de muchas empresas.
Python tanto en las líneas de Machine Learning como de Time Series nos presentan numerosas herramientas para realizar nuestro trabajo de Forecast. Los modelos tienen diferentes orientaciones y usos, una de las diferenciaciones pueden los resultados que se esperan sean arrojados por el modelo, estos pueden ser:
De clasificación. Estos modelos utilizan valores pasados y realizarán predicciones de clasificación binaria, es decir cumple o no cumple, 1 o 0, entre otros. Ejemplos prácticos pueden ser la predicción de si un cliente abandona o no el servicio, es de riesgo o no, probabilidad de compra si o no, entre otros.
De regresión. En estos modelos utilizamos datos históricos para la predicción de valores continuos futuros, por ejemplo: precio, sueldo, edad, etc. Podemos incorporar múltiples variables independientes para la predicción de la variable dependiente.
Como podemos ver, tanto los modelos de clasificación como de regresión utilizan datos pasados para sus predicciones y a su vez, son considerados algoritmos de aprendizaje supervisado. La diferencia es el tipo de problemas para los que son utilizados, los modelos regresivos son para predecir los valores continuos como precio, sueldo, edad, etc. y los algoritmos de clasificación se utilizan para predecir / clasificar los valores discretos como Masculino o Femenino, Verdadero o Falso, Spam o no spam, etc.
Los modelos de Time Series tradicionales son desde sus inicios del tipo regresivos y se utilizan para predecir en base a datos pasados, valores futuros continuos como precio, ventas, temperaturas, utilización, entre otros. Estos modelos en su mayoría son del tipo univariantes, por lo tanto, a partir de una variable independiente, para el caso representada por el tiempo, se tiene por objetivo predecir una variable dependiente tal como podría ser ventas, precios, temperaturas, entre otros.
Muchas veces necesitaremos mejorar nuestros Forecast preparados con Time Series, dependiendo del modelo que utilicemos podremos incorporar por ejemplo fechas de eventos especiales que afecten nuestra predicción, por ejemplo, muchas empresas de retail tienen marcadas diferencias en sus ventas en fechas de navidad y otras fechas especiales. Para estos casos hay modelos que permiten incorporar estos eventos. Además, también encontraremos opciones de incorporar otras series para ayudar al modelo a predecir la tendencia futura de nuestra variable target, por ejemplo, para empresas automotrices probablemente junto a las fechas, también tengan implicancias en sus ventas la tasa de desempleo del país y/o el tipo de cambio peso dólar y/o plazos de entrega, entre otras variables propias de cada tipo de negocio. En resumen, junto a las fechas, podemos mejorar nuestros Forecast incorporando fechas de eventos específicos que afectan el resultado, otras series con implicancias en los resultados tales como tasa desempleo, IPC, tipo de cambio entre otros.
Las clases serán online transmitidas en vivo con participación dinámica, preguntas y respuestas instantáneas, similar a una clase presencial, pero con el respaldo grabado de la clase con sus contenidos y preguntas.
El curso se hará en ambiente Windows.
Sesiones online en vivo
Cristian Saavedra. Ingeniero Industrial MBA. 15 años de experiencia profesional en importantes empresas nacionales e internacionales. Participación en proyectos de abastecimiento y TI.
Juan Ávila. Ingeniero Informático con 13 años de experiencia profesional. Participación en proyectos TI de diversas complejidades. Dominio de varios lenguajes de programación.
Georgina Garrido. Ingeniero Informático con 15 años de experiencia profesional. Participación en proyectos TI para la banca y retail.
Gonzalo Fernández. Estudiante Ingeniería Civil Informática. Programador full stack, Profesor y Ayudante Universitario. 10 años de experiencia.